퀵 정렬 (quick sort)
이해하기 쉽고, 장황하지 않은 자료를 기반으로 강의를 진행합니다.
9. 대표적인 정렬5: 퀵 정렬 (quick sort)¶
1. 퀵 정렬 (quick sort) 이란?¶
- 정렬 알고리즘의 꽃
- 기준점(pivot 이라고 부름)을 정해서, 기준점보다 작은 데이터는 왼쪽(left), 큰 데이터는 오른쪽(right) 으로 모으는 함수를 작성함
- 각 왼쪽(left), 오른쪽(right)은 재귀용법을 사용해서 다시 동일 함수를 호출하여 위 작업을 반복함
- 함수는 왼쪽(left) + 기준점(pivot) + 오른쪽(right) 을 리턴함
2. 어떻게 코드로 만들까?¶
퀵소트 알고리즘에 대해서는 위에서 언급이 되었으므로, 이를 구현하기 위한 세부 코드에 대해 연습을 통해 이해합니다.
프로그래밍 연습
다음 리스트를 리스트 슬라이싱(예 [:2])을 이용해서 세 개로 짤라서 각 리스트 변수에 넣고 출력해보기
다음 리스트를 리스트 슬라이싱(예 [:2])을 이용해서 세 개로 짤라서 각 리스트 변수에 넣고 출력해보기
data_list = [1, 2, 3, 4, 5] 출력: print (data1) print (data2) print (data3) [1, 2] 3 [4, 5]
In [1]:
data_list = [1, 2, 3, 4, 5]
data1 = data_list[:2]
data2 = data_list[2]
data3 = data_list[3:]
In [2]:
print (data1)
print (data2)
print (data3)

프로그래밍 연습
다음 리스트를 맨 앞에 데이터를 기준으로 작은 데이터는 left 변수에, 그렇지 않은 데이터는 right 변수에 넣기
다음 리스트를 맨 앞에 데이터를 기준으로 작은 데이터는 left 변수에, 그렇지 않은 데이터는 right 변수에 넣기
data_list = [4, 1, 2, 5, 7]
In [3]:
pivot = data_list[0]
In [4]:
for index in range(1, 5):
print (index)
프로그래밍 연습
다음 리스트를 맨 앞에 데이터를 pivot 변수에 넣고, pivot 변수 값을 기준으로 작은 데이터는 left 변수에, 그렇지 않은 데이터는 right 변수에 넣기
다음 리스트를 맨 앞에 데이터를 pivot 변수에 넣고, pivot 변수 값을 기준으로 작은 데이터는 left 변수에, 그렇지 않은 데이터는 right 변수에 넣기
In [8]:
data_list = [4, 1, 2, 5, 7]
left = list()
right = list()
pivot = data_list[0]

In [9]:
for index in range(1, 5):
if data_list[index] < pivot:
left.append(data_list[index])
else:
right.append(data_list[index])
In [10]:
print (left)
print (right)
프로그래밍 연습
data_list 가 임의 길이일 때 리스트를 맨 앞에 데이터를 기준으로 작은 데이터는 left 변수에, 그렇지 않은 데이터는 right 변수에 넣기
data_list 가 임의 길이일 때 리스트를 맨 앞에 데이터를 기준으로 작은 데이터는 left 변수에, 그렇지 않은 데이터는 right 변수에 넣기
import random data_list = random.sample(range(100), 10)left = list() right = list() pivot = data_list[0]
for index in range(1, -----------------): if data_list[index] < pivot: left.append(data_list[index]) else: right.append(data_list[index])
In [11]:
import random
data_list = random.sample(range(100), 10)
left = list()
right = list()
pivot = data_list[0]
for index in range(1, len(data_list)):
if data_list[index] < pivot:
left.append(data_list[index])
else:
right.append(data_list[index])
print (left, pivot, right)
프로그래밍 연습
data_list 가 다음 세 데이터를 가지고 있을 때 리스트를 맨 앞에 데이터를 기준으로 작은 데이터는 left 변수에, 그렇지 않은 데이터는 right 변수에 넣고 left, right, pivot 변수 값을 사용해서 정렬된 데이터 출력해보기
data_list 가 다음 세 데이터를 가지고 있을 때 리스트를 맨 앞에 데이터를 기준으로 작은 데이터는 left 변수에, 그렇지 않은 데이터는 right 변수에 넣고 left, right, pivot 변수 값을 사용해서 정렬된 데이터 출력해보기
data_list = [4, 3, 2]

In [12]:
data_list = [4, 3, 2]
left = list()
right = list()
pivot = data_list[0]
for index in range(1, len(data_list)):
if data_list[index] < pivot:
left.append(data_list[index])
else:
right.append(data_list[index])
print (left, pivot, right)
3. 알고리즘 구현¶
- quicksort 함수 만들기
- 만약 리스트 갯수가 한개이면 해당 리스트 리턴
- 그렇지 않으면, 리스트 맨 앞의 데이터를 기준점(pivot)으로 놓기
- left, right 리스트 변수를 만들고,
- 맨 앞의 데이터를 뺀 나머지 데이터를 기준점과 비교(pivot)
- 기준점보다 작으면 left.append(해당 데이터)
- 기준점보다 크면 right.append(해당 데이터)
- return quicksort(left) + pivot + quicksort(right) 로 재귀 호출
리스트로 만들어서 리턴하기: return quick_sort(left) + [pivot] + quick_sort(right)
In [16]:
import random
data_list = random.sample(range(100), 10)
In [17]:
def quick_sort(data_list):
if len(data_list) <= 1:
return data_list
left, right = list(), list()
pivot = data_list[0]
for index in range(1, len(data_list)):
if pivot > data_list[index]:
left.append(data_list[index])
else:
right.append(data_list[index])
return quick_sort(left) + [pivot] + quick_sort(right)
In [18]:
quick_sort(data_list)
Out[18]:
프로그래밍 연습
위 퀵정렬 코드를 파이썬 list comprehension을 사용해서 더 깔끔하게 작성해보기
위 퀵정렬 코드를 파이썬 list comprehension을 사용해서 더 깔끔하게 작성해보기
In [ ]:
def quicksort(data_list):
if len(data_list) <= 1:
return data_list
pivot = data_list[0]
left, right = list(), list() # 다른 언어에서 잘 보지 못하는 구문 (다른 언어에서는 각각 다른 라인에 작성해야 함)
left = [data for data in data_list[1:] if data <= pivot]
right = [data for data in data_list[1:] if data > pivot]
return quicksort(left) + [pivot] + quicksort(right)
4. 알고리즘 분석¶
- 병합정렬과 유사, 시간복잡도는 O(n log n)
- 단, 최악의 경우
- 맨 처음 pivot이 가장 크거나, 가장 작으면
- 모든 데이터를 비교하는 상황이 나옴
- O($n^2$)
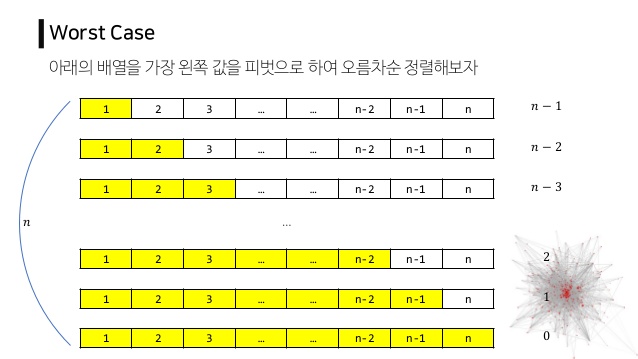
- 단, 최악의 경우
프로그래밍 연습
지금 설명한 퀵 정렬을 지금 다시 스스로 작성해보세요
지금 설명한 퀵 정렬을 지금 다시 스스로 작성해보세요